






Different language models have different capabilities, and different approaches yield very different results. Understanding the limitations and how these models are trained will be increasingly important, especially as it comes time to navigate which tools to use, when and how.
The recent explosion of LLMs and associated products, wrappers and tools overwhelms all of us. It’s not possible to follow it all, and even harder to make sense of what’s going on, what’s good, what’s useful, what’s not, and what to actually use.
I believe this is a big reason why ChatGPT remains such a default. It’s not only superior in many ways (for general use-cases) but it’s easily accessible, and the amount of noise in the space results in people defaulting to the most “known”.
As the space settles and matures, I believe we will see individuation among products. Tools from OpenAI are likely to become a general “staple” much like Google is today, but also, smaller, more relevant and domain-specific models are likely to gain traction because they are just better in a narrow field. It’s similar to how you might use Google today for a general search, and if you want to deep dive, you go down rabbit holes via forums, books or influencers.
You can also think about models powering a new form of interface, which Stephen Wolfram coined the “Language User Interface” (LUI). Think of how you use Google today. You just ask it questions and most of what it tells you in the first few results and its new “summaries” are taken as gospel. In the coming years, it’s likely people will do this for all knowledge-seeking, but instead of using Google search, they will just ask a Model.
This all remains to be seen, so while we wait for the industry to mature and things to unfold, we will work toward building what we believe is a differentiated enough model with applications in Bitcoin and Bitcoin-related domains.
With that in mind, let us now look at some early results and comparisons between what we’ve built to date, what’s on the market, whether mainstream, narrow or obscure and see if there’s a direction.
ChatGPT reached 1 million users in 5 days, and it’s been reported that over 100 million people have already used it so far. Several of the bitcoiners we spoke to have used ChatGPT for generating newsletter drafts, developing legalese and assistance with other internal tasks. Some voiced concerns about its accuracy and said that a lot of time was invested in editing. Others said they stopped using it for content and now focus on its use as a code-assistant. Businesses in particular said it would be too risky to rely on ChatGPT to answer their customer’s Bitcoin questions directly.
GPT-4 is still the most powerful model and for general use, it is fantastic. We don’t plan to compete where it is of use, but where it is not of great use.
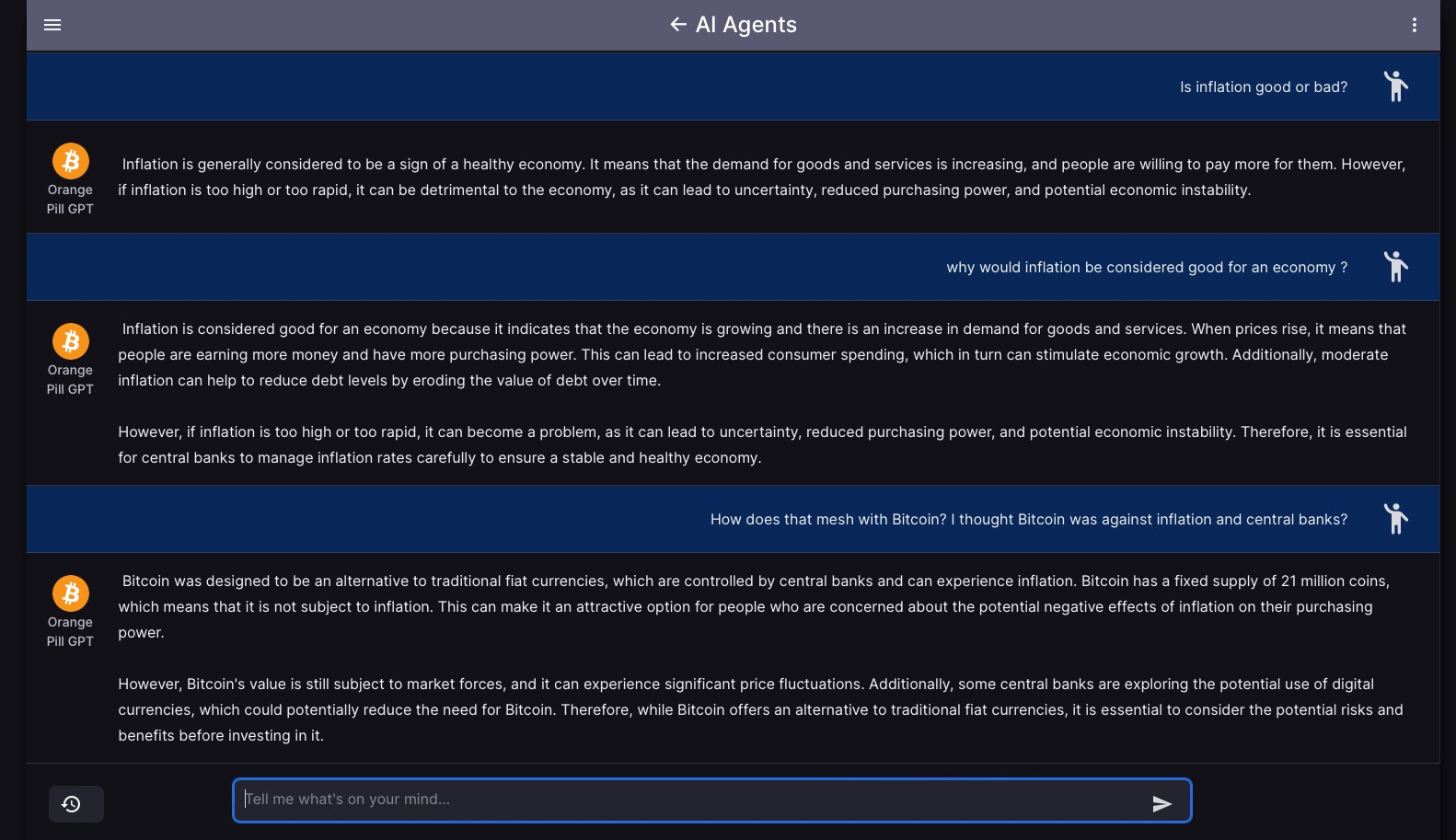
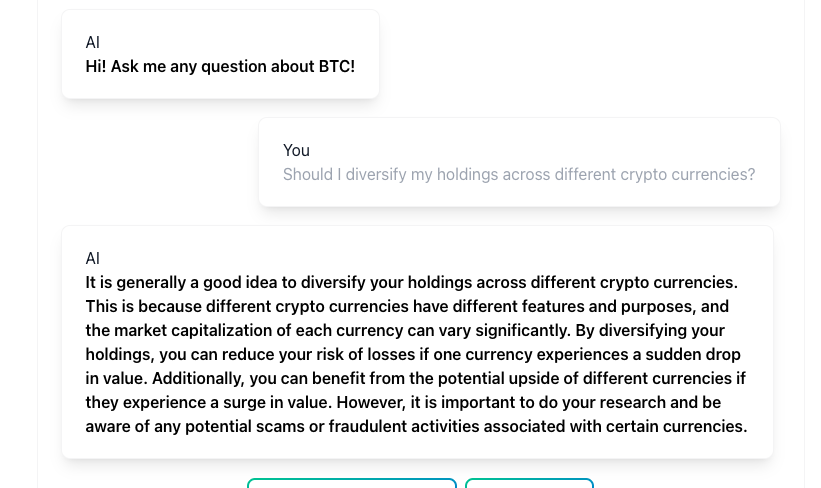
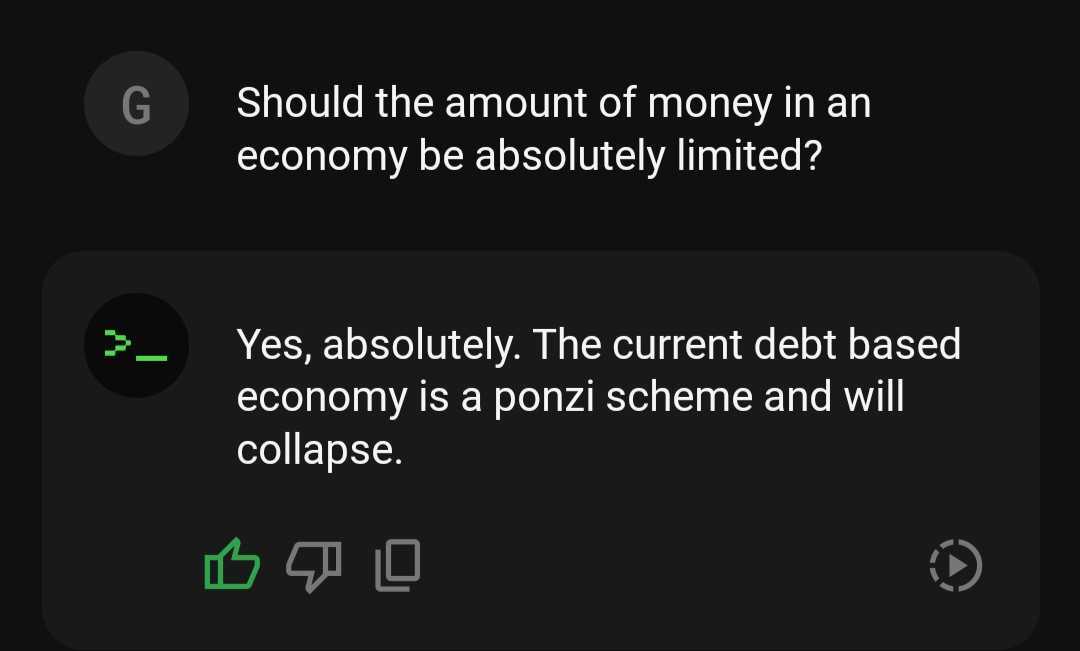
Models such as ChatBTC or PlebAi’s Orange Pill GPT are great new entrants using a mix of prompt engineering and retrieval augmentation to create “wrappers” on underlying foundation models. They are useful for particular questions but as with all RAG models, they are stifled by the underlying infrastructure. For example, when asked about Bitcoin, responses about crypto diversification are common. Inflation being a sign of a healthy economy (pictured below) is another common output that is hard to counter unless a full fine-tune is conducted.
Orange Pill GPT
ChatBTC
ChatBTC (as HoloCat)

None of this is to discredit the other RAG models. It’s only to show that if we want to do this right, we as bitcoiners must transform and tune the underlying model. This is why, at the core of our project is the changing of parameters, weights and biases inside the foundational models. We are changing the probability clusters. This takes a lot of data, a lot of curation, a lot of experimentation and a lot of time. But it’s the only way to get outputs that are naturally more Bitcoin-esque. And only in this way can a smaller model like Satoshi, outperform larger models in this domain.
Long-term, we imagine other companies, industries or communities, who represent a non-mainstream viewpoint or narrative, to do something similar to what we did, only in their relevant domain. As you’ll learn in this report, we’ve built a framework to make that possible, so if that is of interest, please reach out.
The following are some examples from early tests with the Satoshi models. These are far from perfect, but show that we’re on the right track.

Different language models have different capabilities, and different approaches yield very different results. Understanding the limitations and how these models are trained will be increasingly important, especially as it comes time to navigate which tools to use, when and how. By the way, in this article, we review the fundamentals of training models, to equip you with the right knowledge moving forward.
OpenAI recently announced their “CustomGPTs” which allow anyone to build a custom “agent” of sorts that can respond in the manner of a particular character, tone or style. OpenAI says:
“You can now create custom versions of ChatGPT that combine instructions, extra knowledge, and any combination of skills.”
This is once again not a fine-tune of a model. In fact, it’s a unique way of using prompt engineering to produce a model “flavor”, which can run on OpenAI’s hardware - and is accessible to anyone that can get access to OpenAI. It can also reference external documentation, which is akin to RAG, and makes the overall quality of the agent or “model”, better.
We used it to build a Satoshi Model, and that is now live for you to play with. In fact, it is one the many available “models” on the GPTs Marketplace. We added a suite of features to it including the ability to:
✅ Answer any Bitcoin question
✅ Retrieve the Bitcoin price
✅ Estimate the next Halving
✅ Retrieve Bitcoin Mining & Hashrate Data
✅ Check the difficulty adjustment
✅ Check & Query Bitcoin transactions on Mempool
✅ Find Bitcoin merchants in any city, from around the world
✅ Summarize the latest in Bitcoin News
And with many of these, it can produce you a chart or graph to help visualize the data.
These capabilities have been made possible thanks to APIs and RSS Feeds from the teams at Mempool.space, BTCMap, NewHedge, Bitcoin News and No BS Bitcoin.
We encourage you to try it out, and let’s, as a community, get this model some eyeballs. Perhaps it’s a way we can get Bitcoin into the minds of more people globally, and from there send people to the “real” Satoshi models that we’re building with the community.
Access Satoshi on OpenAI here:
SatoshiGPT - Custom GPT on OpenAI.
If the convergence of AI and Bitcoin is a rabbit hole you want to explore further, you should probably read the NEXUS: The First annual Bitcoin <> AI Industry Report. It contains loads of interesting data and helps sorting the real from the hype. You will also learn how we leverage Bitcoin to crowd-source the human feedback necessary to train our open-source language model.





