






This guide provides an in-depth look into fine-tuning the 87B MoE model from Mistral AI for specific data applications.
In this comprehensive guide, we will explore the process of fine-tuning Mistral AI's Mixture of Experts Model (specifically, the 87B variant) on your dataset. This technique is critical for leveraging the power of large language models (LLMs) in a way that's tailored to your specific data and use case. A mixture of experts (MoE) models has garnered significant attention lately, with speculation that models like GPT-4 could potentially be MoE-based. The 87B MoE model from Mistral AI is renowned for its performance, even outperforming GPT-3.5 on various benchmarks.
We will cover all aspects of this process, from initial setup and data formatting to model training and evaluation. By the end of this guide, you should be well-equipped to fine-tune the 87B MoE model on your dataset, potentially enhancing its capabilities for your specific applications.
Before diving into the fine-tuning process, ensure you have the following prerequisites ready:
- Hardware: Approximately 60-65GB of VRAM is required. Access to four T4 GPUs or an H100 GPU is advisable for efficient training.
- Software: You will need to install necessary packages such as transformers, TRL, accelerate, pytorch bits and bytes, and the hugging face datasets library.
- Dataset: Have your dataset ready, formatted appropriately for the model. This guide will use the Mosaic ML instruct V3 dataset as an example.
Begin by installing the necessary packages. Open your terminal or command prompt and execute the following commands:bash
pip install transformers
pip install TRL
pip install accelerate
pip install pytorch bits and bytes
pip install huggingface datasets
These packages will provide the tools needed to handle the model, training, and dataset manipulation.
Examine your dataset closely. It should have a structure conducive to what the model expects. For the MoE 87B model, you should format your data into a single column with a specified prompt template. Here’s a simplified version of the prompt template:[special tokens][system message][user input][special token indicating end of user input][model-generated response][special token indicating end of model response]
Create a Python function that reformats your dataset into this structure. For instance:python
def create_prompt_template(data):
# Your code to format each data entry according to the prompt template goes here.
return formatted_data
For a more challenging setup, you can rearrange the data to ask the model to generate questions based on provided text, which introduces an additional level of complexity to the fine-tuning process.
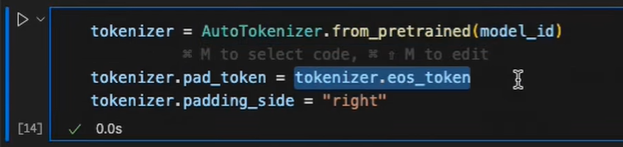
Load the base MoE model using the Transformers library. Set up the configuration for the training, including the precision (e.g., training in 4 bits but computing in 16 bits) and enabling flash attention if supported by your hardware. Load the tokenizer and establish the end-of-sequence tokens and padding for variable-length inputs.
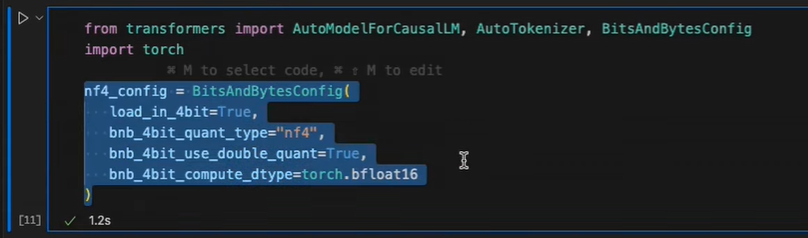
Tokenize your dataset using the loaded tokenizer. Determine the maximum sequence length by analyzing the distribution of token lengths in your dataset. This step is significant as it impacts computational efficiency. You can visualize the distribution with a histogram and select a max sequence length that covers most of your data.
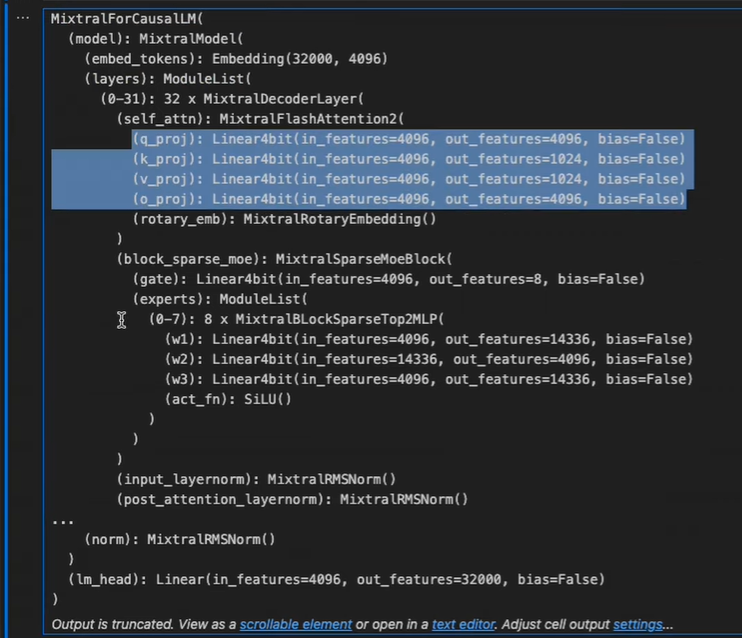
Familiarize yourself with the architecture of the MoE model, particularly the linear layers, as they will be targeted with Lora adapters. Configure the Lora settings, including which layers to attach the adapters to, the dropout rate, and other parameters to minimize overfitting and enhance training.
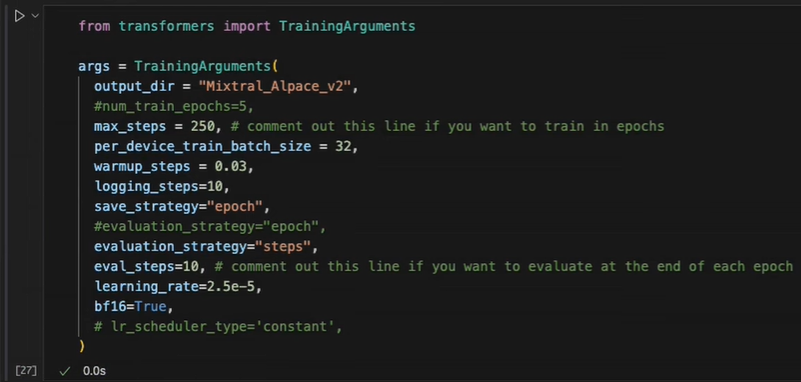
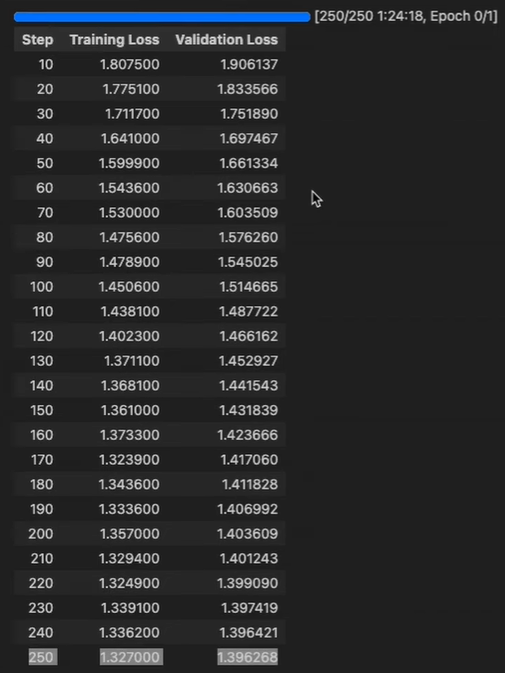
Set up the hyperparameters for training, such as the number of epochs, batch size, learning rate, and whether to enable parallelization for multiple GPUs. Use the TRL package from Hugging Face to define your training setup and start the training process. Monitor the training and validation loss to ensure that the model is learning effectively without overfitting.

After training, evaluate the model's performance by using it to generate responses based on prompts. Compare the responses before and after fine-tuning to assess the improvement.
Finally, save the trained model locally and consider sharing it with the community by uploading it to the Hugging Face model hub. Make sure to merge the base model with the trained Lora adapters before using or sharing it.

Fine-tuning a model like Mistral AI's 87B MoE on your dataset requires careful preparation, a solid understanding of the model architecture, and meticulous handling of the training process. By following the steps outlined in this guide, you can tailor the model to better suit your data and potentially unlock more powerful and relevant capabilities for your specific use case. Remember to experiment with hyperparameters and training configurations to achieve the best results, and always keep an eye on the model's performance to prevent overfitting.





