






People talk about “data quality” a lot, which is fundamentally what good training is all about, yes, but rarely does anyone define what quality actually means. If you’re a Bitcoiner, you’re probably familiar with ideas like “subjective value”, and it applies in this case.
To build Spirit of Satoshi, we decided early on that a community-driven approach to training and tuning the language model would be necessary. This involves many moving parts, which we’ll explore in the following pages. It starts off with a growing repository of bitcoin and bitcoin-related knowledge that is being used to generate an initial dataset for the model. It’s followed by a pipeline of automated and partially-automated processes to manipulate and transform data. Participants from the community are then incentivized to verify the accuracy of this data, to answer questions as if they’re the “model” and to rank responses, all in order to enhance the quality of the initial dataset.
This process is then followed by a final check and refinement of the data, before it is added to the corpus for “training,” after which point the compute element comes into play. Finally, after the training is done, there are two things remaining. First, is a basic evaluation, followed by reinforcement learning, for alignment.
Let's give you a deep insight into the details of this process.
It’s not enough to just go and collect a library of books, scrape a bunch of websites and “feed it to the model”. That’s not how things actually work.
Language Models are a kind of mirror of the aggregate of the data you “feed” them. If you want a model to answer questions, you have to feed it Q&A examples. You cannot simply feed it entire books or essays, because it will attempt to regurgitate entire books or essays in its response. In fact, “training” a model refers just as much to the content you are feeding it, as it does to the format you are feeding it.
This was a huge learning for us in the early days, and something that’s not quite made clear when language models are discussed online.
People talk about “data quality” a lot, which is fundamentally what good training is all about, yes, but rarely does anyone define what quality actually means. If you’re a Bitcoiner, you’re probably familiar with ideas like “subjective value”, and it applies in this case. Data quality is subjective - and it depends largely on how you want the model to behave or perform.
You get the point.
For us, building a model that is good at answering Bitcoin along with economic, cultural and political questions in a Bitcoiner/Austrian-econ way was the primary goal. As such we opted for the Q&A route as the primary form of example in the training dataset. We also used paragraphs extracted from books, essays, articles and the like (data blend), but the weighting was more skewed to Q&A variations of these.
As you can imagine, this is not a quick and easy process. Imagine taking just ONE book (for example, the Bitcoin Standard), and breaking it up into 1000 individual chunks. Then having to extract a question and answer pair (or multiple) from each individual chunk. And then having to ensure that those Question and Answer pairs are actually relevant, accurate, and maintain the integrity of the Author’s voice, tone and language.
Now imagine multiplying that by every book, every podcast, every essay, every article - and you start to get an idea for the magnitude of this task.
Luckily for us (and anybody else out there), this process can be partly automated, using - you guessed it - other language models! This of course comes with its own challenges, and we shall explore this as we proceed, but it’s important to note that the primary reason the cost of training models has “come down” is that manipulating large quantities of data can now be done using an OpenAI API endpoint. GPU costs have not necessarily come down (a lot) and are not really where the majority of the costs lie (with respect to “training” at least - different story with inference).
Before we dig into the specifics, see the diagram below, to better visualize the pipeline we built for automating parts of this process, and streamlining it.
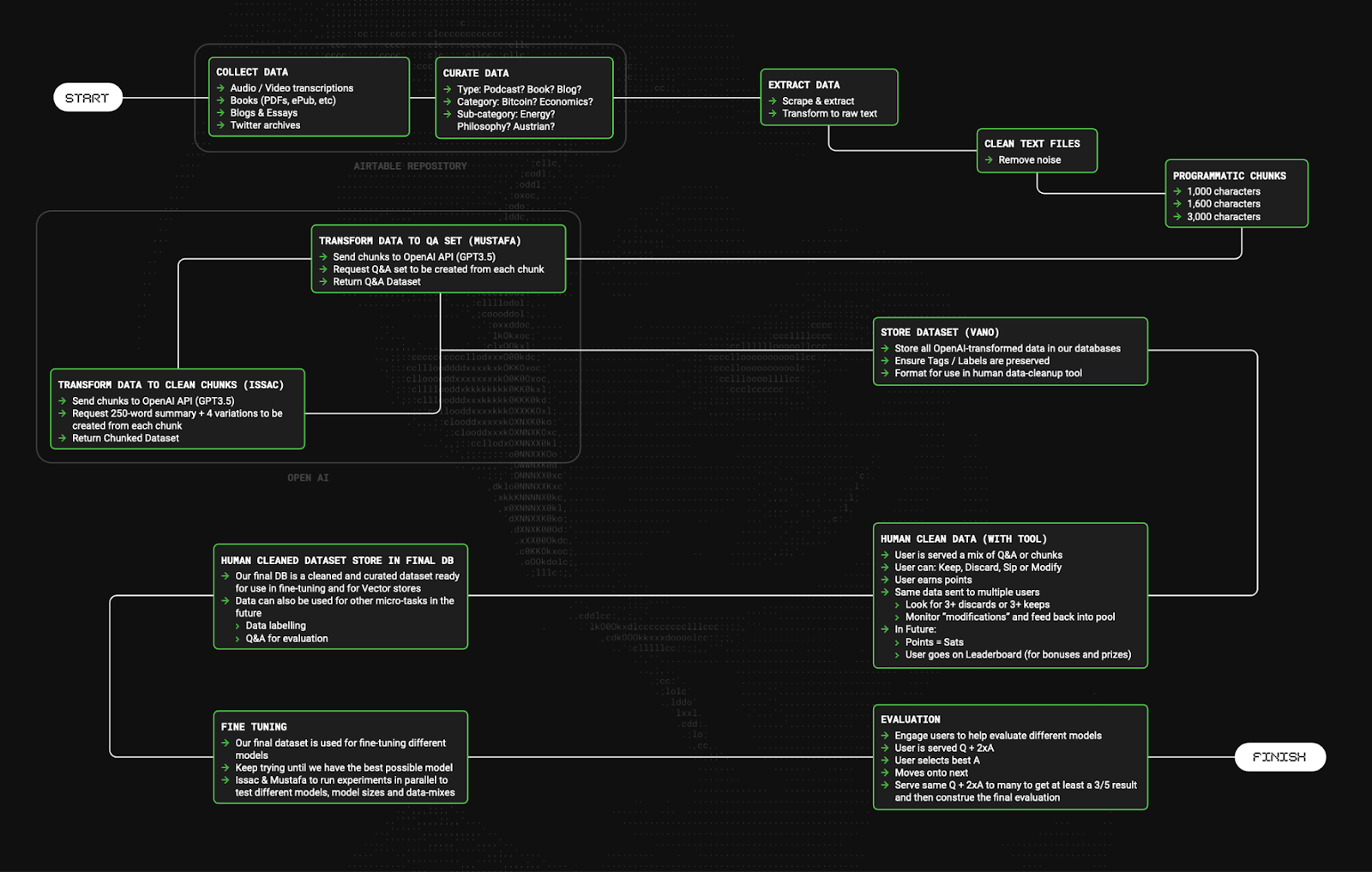
Let’s begin.
In this stage, we are simply gathering data. Books, essays, articles, directories, podcasts, YouTube videos, tutorials. You name it.
To make the process easier and involve the community, we created The Nakamoto Repository. A public Airtable that anybody can search, and append data to - either as a link, text file or PDF. Of course, before it is officially added to the repository, we ‘approve’ it internally.
The mandate is quite broad. “Anything that is Bitcoin or Austrian or Libertarian-esque”.
In other words, if someone uploads an episode of Bankless, or an article by Charles Hoskinson, it will not be approved. Most other things do get approved.
The cool thing about this repository is that everything is tagged by Author, date published, format, etc - and because it’s public, anyone can search this for links to sources. We hope one day to make it more useful, ie; to perhaps one day create it as a library for anyone to actually download from. But that’s another project entirely.
As the name suggests, this component is about actually extracting the data. It’s no good having links and books and audio files. Training a language model requires raw text, in a particular format.
This section can get painfully tedious because it requires the use of all sorts of different format conversion tools, scrapers, transcribing tools, and more. There are great ones out there, and the team at Stakwork are doing a brilliant job with transcriptions for Bitcoin podcasts, but nevertheless it’s a time-consuming process.
Once extracted, the files need to be cleaned and formatted. When you think of cleaning, imagine that a book has a table of contents in it, title pages, periods and spaces which look fine on a book or article, but completely useless (and in fact a hindrance) for what needs to be fed to a model. There are once again tools to automate a large chunk of this process, but it’s also tedious and requires, as Paul Itoi could call it, “Wrestling with the tools”.
Finally, once this is done, you can break the raw data up into chunks. The simplest way to do this is to just set a “token length” into a chunking tool and let it do the work. Of course, this is blind, so you will get chunks that cut paragraphs off mid sentence or mid idea. This is not easy to get around, which is why the next stage of data manipulation exists.
This is the point where we begin to use other language models. Quite frankly, OpenAI is the best for this process, but comes with its own (significant) challenges. Let’s explore.
What we’re trying to do here, is programmatically take these chunks and:
Sounds simple right?
Well…that’s what we thought. Until, you try it. And instead of completing or rounding out the chunk, the model rewrites it, talking about crypto and removing the original Author’s tone, voice and language. Or, the Q&A pairs extracted have embedded in them social justice initiatives such as “how can this relate to increasing inclusivity in the bitcoin community”.
What????
This is not what I asked for! So you go back and try again, and again, and again. You spend hundreds of hours wrestling with the model to ensure that it doesn’t inject stupidities, its own watered down language or other artifacts into these transformed chunks. And it’s still not perfect. Roughly 5 - 10% of the data that's transformed still has “this author” or “based on the provided context” injected (which you don’t want), or worse, it changes the entire tone of the language - particularly when its something written by the likes of Saifedean, Svetski and other more “out of the Overton window” authors.
In this process, we became prompt engineering experts. When you finally get something that does mostly what you want it to do. Then you have to create multiple variants because the tonality, language style and voice changes from author to author, and text to text.
Finally, you then run that at scale, and you produce thousands upon thousands of “cleaned up chunks” and “Q&A pairs”. Only to find that the model only did what you wanted it to do, 50% of the time. Despite the “perfect prompt”!
So you go back and play again. You break up the process into smaller steps. And you keep wrestling, until you have a better result.
Of course, you cannot go and manually read all of these, so we actually built some micro-evaluation models to score these chunks and Q&A pairs. This helped us speed up the process of checking - but it’s still not perfect.
Which brings us to the next step!
Yep. You read that right. We’re in the age of AI, and we still need humans to get this data through the last mile! Ironic right. This is in fact, where a lot of the time and money in the AI space is actually spent.
💡 Fun fact. You are likely to get a better fine tune out of 500 examples of highly accurate, human-generated data, than you are with wrestled and cajoled language model-generated-data that’s orders of magnitude larger.
And this is precisely the stage where a Lightning-enabled incentivization platform comes into play. Sure, you can pay people to do this using old fiat rails, but that’s cumbersome, slow, expensive, and delayed.
If you really want human input, at scale, real time payments are a huge benefit. In fact, if you can make it anonymous too, so that anyone, anywhere can participate, you open the opportunity space up much further (which of course brings with it its own challenges).
How did we do this?
First of all - we wanted to allow anyone to participate, assuming they had some sort of Bitcoin knowledge. How to check for this? Well - we set up a very low-tech way to screen contributors. If you are interested in training satoshi, you can “apply” to be a trainer. You can do this now if you wish. It’s a simple form you can access here: Help us train Satoshi.
You answer some screening questions, and the results are sent to us. We check the results, and based on some internal heuristics, add you to the training app (or not).
This deals with probably 80% of the potential noise you can introduce. The balance is dealt with using a novel consensus mechanism. Because we conducted the initial screening relatively manually, we’re certain most of the participants are Bitcoiners (further validated by their engagement in our telegram group). This means, a majority consensus will generally lead to a high degree of accuracy for each piece of validated data, and data generated.
We are obviously not going to divulge that precise consensus mechanism, else it would quickly be gamed and made useless. Instead I will explain what we are actually doing inside the training app.
There are 3 primary functions in the data cleaning & verification stage.
As data is created, verified and accepted, you can almost imagine it as a sausage machine. What comes out the other end is high quality data that can be used for the actual “training” stage. You can also imagine this requires quite a lot of people to really do at scale - and is why we’re extremely thankful to one of the greatest communities on earth: Bitcoiners. I’m not sure doing something like this would be possible (at least not to the same degree) elsewhere. We had incredible, dedicated contributions made from people all over the world.
For now, let’s move onto the next step.
I always use air quotes around the word training, because while it’s the best word we have for the process, it’s very different to how training works in humans. It’s also used interchangeably with “tuning” or “fine-tuning”. In fact, there is no set term because the processes of tuning and training, while some argue are different, are essentially the same. They involve taking, in our case; all of this now-clean data, ensuring it is comprised of the right blend (ie; if you want a better question answered, you need to include more Q&A, etc.) and formatting it one more time in preparation for “training” or “tuning” (which are similar).
This is where the GPUs come into play. This is when you “feed” the data to the model.
Training requires the use of different frameworks, which we will not get into here, but there is everything from Lightning AI, Sagemaker, GCP has its own and of course a myriad of others.
The process is quite opaque. It’s not clear what’s happening internally, and it’s only when the “final model” is returned, that you can test it. This is the reason why I call training more “art” than “science”. It is a highly experimental process, which yields different results depending not only on the data blend and the model framework, but also things like the number of epochs you train it, the type of training (full tune, low-rank) and much more.
I’d like to make clear that training a model from scratch was well beyond our means. This is a multi-million dollar undertaking.
Instead, we took a variety of approaches to fine tuning existing open source models (Llama, Mistral, Llama 2, Mosaic, Red Pyjama) with our data set. We found that getting the model to unlearn the “mainstream” biases intrinsic to these open sourced models was quite difficult. Not only was style and language continually affected, but strange artifacts were extremely difficult to remove, despite multiple tunes. We started our training with a Low Rank Adaptation (LoRA) approach to fine-tuning, primarily on the 7B Llama 2 model (seven billion parameters), which is Meta’s latest Open Source foundational model.
LoRA allows you to tune a model at a lower cost because you don’t have to tune the entire set of model parameters. Full fine-tunes are more expensive because you are adapting parameters at every layer of the model’s architecture. LoRA lets you change a smaller subset of weights and biases, for example 2-5% of the parameters, and get ~80% of the results. For testing purposes, this is fantastic, but for an end product, we found the results were not so great.
Moving to the larger Llama 2, 13B and repeating the process improved the results, however, it’s not enough, which is why post training alignment is necessary (Stage 4 below).
Once this first training stage is complete, you need to work out what you’ve accomplished. Of course, you can just “plug the model in and ask it some questions” to quickly get a sense for the result - but a more comprehensive way to do this is using an evaluation or benchmarking tool.
This involves two parts. One is a set of benchmark questions or tasks that the model is asked or fed. The second is some way of evaluating the responses or results and scoring them. Most evaluations are fully programmatic these days. In other words, there is some sort of scoring model used to evaluate the results. This is fine, but once again, human evaluations are superior. While we’ve not built a product here, a Lightning-enabled evacuation tool has been on our roadmap for some time. This would allow the same community to rank or score responses and in turn (with some sort of other, novel consensus mechanism) to earn Bitcoin and be paid out in real time for their contribution.
We have used a blend of internal human evaluation (ie; our team) along with some programmatic approaches.
I should also note that we have built the most comprehensive benchmark set of questions for a Bitcoin model to be tested against. It is 500 of the most important, common, pertinent and nuanced questions in Bitcoin. It is this set that we’re training our model to perform well against and invite anybody else working on a Bitcoin-related model to come and test against this question set!
Once this initial evaluation is complete, you get a sense for where the model is weak, where it is strong and where it needs further alignment. Reinforcement learning is a bit like fine-tuning but more dynamic. It’s often called RLHF (Reinforcement Learning by Human Feedback) which has proven to be the most effective (once again, human involvement - sensing a theme?).
There is also RLAIF, which is similar but using purely model responses as the reinforcement examples. The latter is not as effective, but can be done faster. The key is to find a balance between both, because the RLHF process can quickly become expensive.
There are also different means of implementing the RL stage. Two of the more effective are PPO (Proximal Policy Optimisation) and more recently, DPO (Direct Preference Optimisation). With PPO, the learning is step-by-step, based on immediate feedback. In DPO, learning comes from comparing finished products and picking the better one. Both are effective and once again, the process is experimental.
Once again, this step of model training is ideal for a Lightning-enabled platform to engage human participants. We have actually built this and will roll the feature out shortly in our training app. It will primarily consist of the user ranking multiple answers to a single question. The best will then be used (in aggregate) to train a reinforcement model that will perform either PPO or DPO.
Once some level of “alignment” is achieved, we reach the final evaluation stage. This is not so different from the preliminary eval, except that you are hoping to see a change in the results and a higher overall score.
If you’ve done a good job with the data, in the first place, and you add a little bit of luck into the magic that is “training” the model, you should come away with a positive result. This is not always the case, because small changes or mishaps upstream can turn into bigger issues later. But that’s just the nature of the process - and why I call it more art than science at this stage. I am sure this will change as the industry matures, but I hope it’s been made clear. We are in the very early days and much more experimentation needs to be done before it becomes more science than art.
If the convergence of AI and Bitcoin is a rabbit hole you want to explore further, you should probably read the NEXUS: The First annual Bitcoin <> AI Industry Report. It contains loads of interesting data and helps sorting the real from the hype. You will also learn how the 50 Bitcoin companies we interviewed expect GenAi to enhance their operational effectiveness.





